
Dans ce 3ème article de notre série qui revient sur les décisions que nous avons prises chez Rbean, nous allons parler des évaluations.
Et nous allons pas mal parler de parcours d’informatique, puisque c’est sûrement le meilleur domaine pour l’utilisation des outils de correction automatique.
Pour avoir un exemple concret, je vais parler de notre Bootcamp Python.
Mais tout le système de corrections humaines (que nous verrons plus bas dans l’article) est aussi valable pour des parcours non-tech.
Les corrections automatiques dans un parcours d’informatique : la Sentinel
Comme nous le disions dans le premier article qui revenait sur le format des piscines (des bootcamps), les notions de correction automatique et de piscine vont de pair.
En effet, depuis au moins la création des piscines de C à Epitech, les piscines ont toujours été corrigées par des outils de correction automatique. Dans ces écoles, elle s’appelle la Moulinette, nous, nous l’avons surnommée la Sentinel.
Mais tout d’abord, est-ce qu’une correction automatique est vraiment appropriée en informatique ?
Apprendre le code informatique avec des corrections automatiques
Les deux gros points forts d’une correction automatisée en informatique restent l’objectivité et la vitesse du feedback.
Un outil de correction (qui fonctionne bien) ne se trompera pas. Il ne fera pas de fautes d’inattention et il testera tout ce qu’on lui a demandé de tester. Il peut le faire sur une promo de centaines d’étudiants en quelques dizaines de secondes.
Et comme l’outil est objectif, c’est lui qui a raison s’il y a des problèmes d’interprétation (problèmes qui devraient être corrigés au plus vite en clarifiant le sujet !).
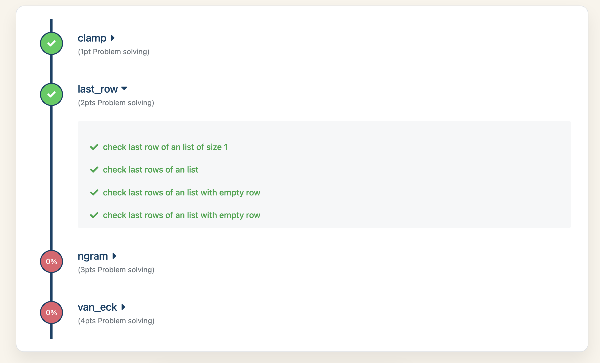
Dans notre Bootcamp Python, chaque nouvelle notion est mise en pratique par une série d’exercices. Ces exercices sont très unitaires et n’ont pas de place pour l’interprétation, ce qui en fait de très bons candidats pour les corrections automatiques.
Pour faire simple, ce sont des exercices où il faut faire une fonction (un bout de code Python) qui prend une entrée, la transforme toujours de la même manière, et la redonne en sortie. La correction automatique peut donc donner une série d’entrées et vérifier les sorties.
Mais où est la limite ?
Les corrections automatiques pour les projets plus complexes ou plus créatifs
Ces petits exercices sont bien lors d’un Bootcamp, mais quand l’étudiant avance dans son apprentissage de l’informatique, il lui faut des projets plus conséquents, où il doit lui-même prendre des décisions sur comment structurer son travail.
Chaque étudiant ayant des livrables structurés complètement différemment, il devient impossible de corriger avec une Sentinel.
Ceci étant dit, nous avons essayé d’autres formats de Sentinel qui ont bien fonctionné, avec des tests utilisateurs pour un site web, par exemple. Mais cela nous oblige tout de même à forcer l’étudiant à avoir des textes ou des URLs bien précis pour que la Sentinel s’en sorte.
Comment éviter la triche lors des corrections automatiques
Comme souvent, notre rôle en tant que concepteurs d’outils pédagogiques (surtout dans l’informatique !) est de trouver des moyens de limiter la triche le plus possible.
Quand j’étais étudiant à Epitech, nous avions des examens à faire tous les samedis. Mais c’étaient généralement toujours les mêmes exercices, et il y avait un exercice où l’outil de correction testait une seule entrée et toujours la même à chaque examen. Au bout d’un moment, au lieu de faire la fonction correctement (ce qui prenait bien 30 min), je renvoyais en dur la réponse qu’attendait l’outil de correction. Et donc, j’avais bon.
Cette expérience m’a finalement assez marqué pour que, quelques années plus tard, lorsque j’ai codé mon premier outil de correction automatique, je génère des tests aléatoires.
Les tests aléatoires sont un bon moyen de contrecarrer les tricheurs, mais il faut s’assurer que nos tests continuent de tester tous les cas. Si une fonction reçoit un nombre en paramètre, il ne faut pas se contenter de générer un nombre au hasard. Il faut tester avec un nombre négatif, un positif, 0, 1, etc.
Notre Sentinel teste également comment l’étudiant a construit son code, pour détecter des anomalies ou de la triche.
Est-ce qu’une correction automatique a d’autres bénéfices ?
Au-delà du fait de donner une note objective à un exercice, la Sentinel pousse les étudiants à être plus rigoureux, une qualité nécessaire chez les développeurs.
Et oui, comme la Sentinel attend une sortie précise, l’étudiant doit respecter scrupuleusement l’énoncé. Les textes “bonjour” et “Bonjour” ne sont pas les mêmes. “bonjour” et “bonjour “ non plus.
On pourrait atténuer ces soucis en étant plus permissif sur ce qu’attend la Sentinel (et c’est quelque chose que nous pourrions essayer à un moment). Mais tous les développeurs vous diront qu’ils ont déjà perdu des heures à cause d’une virgule, d’un espace, ou d’une majuscule.
Prendre l’habitude de faire attention à ces détails le plus tôt possible nous semble nécessaire.
Gamification de la Sentinel
Nous avons également ajouté plusieurs couches de gamification au-dessus de la Sentinel.
Une première couche un peu classique, où à partir d’un certain nombre d’exercices réussis ou réussis d’affilée, on débloque des achievements.
Mais nous avons surtout une deuxième couche qui permet de donner le choix aux apprenants : ils démarrent la série d’exercices avec un nombre de crédits Sentinel, qu’ils peuvent utiliser quand ils le souhaitent. L’utilisation d’un crédit lance la Sentinel, qui note donc leur travail, quand l’étudiant le souhaite.
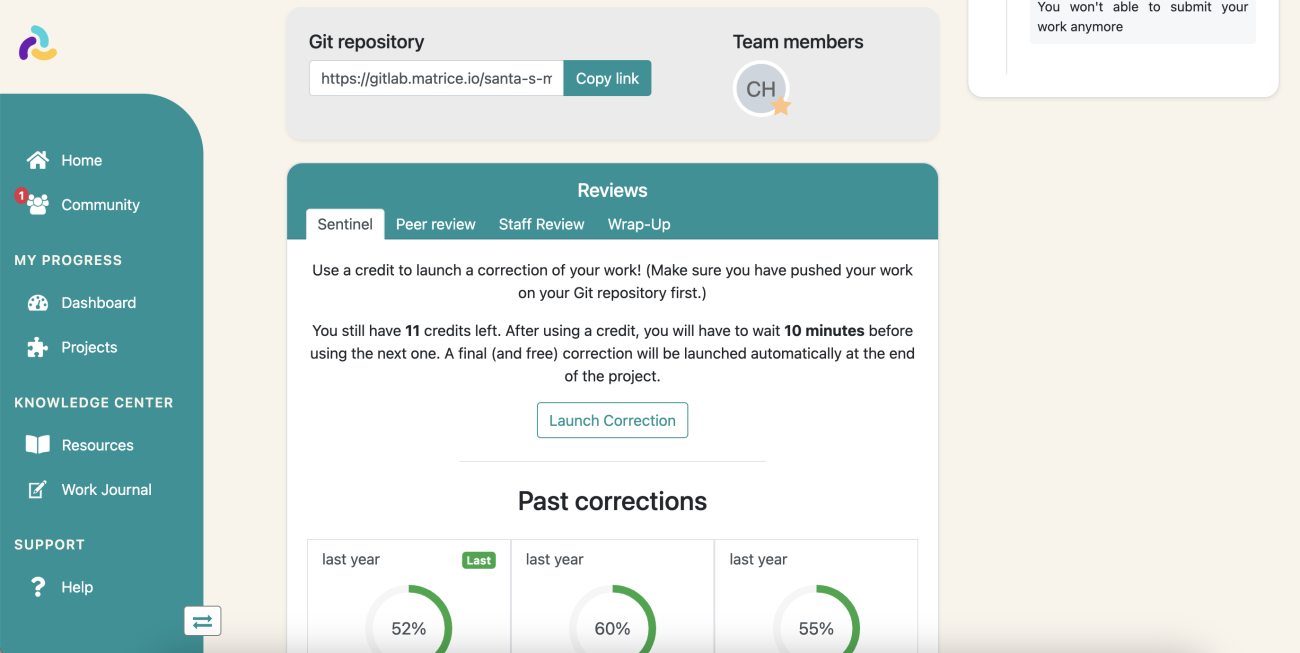
On peut également configurer une période minimum entre deux Sentinel, pour rendre l’action plus marquante.
Cela rend l’étape de la correction plus amusante et, surtout, diminue la frustration qu’une correction automatique peut créer chez l’apprenant.
Les corrections humaines
Les corrections humaines (dans un parcours d’informatique ou non) permettent de donner un feedback aux étudiants, pour leur montrer ce qu’ils ont compris ou non. La personne qui fait la correction pourra ressentir de manière subjective les besoins des étudiants et l’orienter là où il faut.
Mais, faire des corrections humaines peut être long, peut demander un gros temps d’ingénierie pédagogique (pour écrire et maintenir les barèmes) et donc peut coûter cher à un organisme de formation.
Des corrections avec et sans barème sur notre LMS
Pour atténuer cela, nous avons ajouté deux systèmes de notation dans notre plateforme LMS : une avec barème et une sans. Ainsi, les membres du staff peuvent être flexibles sur le niveau de détails qu’ils souhaitent donner aux étudiants.
Le mode sans barème propose simplement au membre du staff de donner un avis (sous forme d’un emoji ou d’une note sur 20) ainsi qu’un commentaire optionnel. Le but est d’être rapide tout en donnant une indication aux étudiants de la qualité de leur livrable.
Le mode avec barème prend plus de temps. Le membre du staff (ou le pair, comme nous le verrons plus tard !) fait une correction complète du livrable. Il a un barème à suivre et doit remplir chacun des points de celui-ci. Une fois complété, le membre du staff peut ajouter un commentaire et une note est générée.
Si la gamification est activée sur le parcours, les étudiants peuvent gagner des points de skills en fonction de leur note.
Une correction par un staff ou par des pairs ?
La correction par les pairs est un sujet compliqué. Nous en parlions dans notre article sur le peer learning, les corrections par les pairs peuvent souvent être source de frustration et de triche.
Le format que nous utilisons personnellement est le suivant :
Nous programmons une correction par les pairs (une peer review) au milieu du projet, avec une note “blanche” (dans le sens où elle ne compte pas vraiment). Le but de la review n’est donc pas de noter son collègue, mais de lui montrer ce qui va et ne va pas, d’échanger avec lui et également d’apprendre grâce à lui. Ce qui est pour nous du vrai peer learning.
Une fois le projet fini, nous programmons une soutenance finale qui est faite par des membres du staff. Cette fois, la note compte. Mais elle n’est pas la plus importante. En effet, nous essayons de faire ces soutenances en face à face quand c’est possible, pour que l’étudiant comprenne du mieux possible les raisons qui lui ont fait obtenir cette note. C’est aussi le moment où l’apprenant peut poser ses questions et clarifier les choses qu’il n’a pas comprises sur le projet.
Comment faire une note finale ?
Comment attribuer une note finale à un étudiant alors qu’il a eu une soutenance entre pairs qui n’apporte pas de note finale, une soutenance staff qui apporte une vraie note, et, disons, une note automatique donnée par la Sentinel ?
Généralement, c’est quelque chose que nous ne faisons pas. Dans nos formations, la notion de note n’est pas la plus importante.
Comme nous l’avons déjà dit dans plusieurs articles, en pédagogie par projet, l’échec n’est pas vraiment un problème tant qu’on a compris ce qu’on attendait de nous et qu’on réussira la prochaine fois.
Mais toutes les formations ne sont pas comme ça, et l’administration française encore moins ! Dans ces cas-là, nous laissons les responsables pédagogiques paramétrer comme ils veulent leurs notes. Ils peuvent également télécharger un Excel avec toutes les notes et procéder comme ils le souhaitent !
Nos pistes sur les évaluations
Avoir des corrections plus liées aux rendus étudiants
Une des pistes de réflexion que nous avons en ce moment concerne les corrections à distance. En effet, quand on fait des formations complètement en ligne et qu’on ne croise jamais vraiment les étudiants, avoir simplement un barème à remplir peut être un peu limité.
Nous réfléchissons donc à comment (techniquement et pédagogiquement) permettre aux membres du staff de commenter plus en profondeur un rendu. Si le rendu est un texte, on pourrait annoter un passage ; si c’est une image, annoter une zone ; ou si c’est une vidéo, annoter un passage.
Le retour fait à l’étudiant sera donc plus précis et probablement plus agréable à lire qu’un gros pavé de texte qui explique toutes les raisons pour lesquelles il a eu faux.
Avoir une Sentinel plus modulable
Cela fait plusieurs années que nous réfléchissons à ouvrir davantage notre Sentinel aux clients de notre plateforme LMS. Leur permettre de configurer eux-mêmes cet outil, sans qu’ils aient à en comprendre les fonctionnements.
Pour l’instant, ils peuvent créer des tests en dur, mais pas encore de tests aléatoires.
Depuis quelque temps, des technologies qui permettraient d’exécuter des bouts de code dans des contextes sécurisés se sont popularisées, et il faut que nous testions cela !
Avoir des corrections plus liées au peer learning
Comme nous le disions dans notre article sur le peer learning et comment nous l’utilisons dans nos formations clé en main, nous réfléchissons à de nouvelles situations de corrections. Par exemple, les concours mettent en avant d’autres aspects d’un projet. Les concours ou les défis peuvent valoriser un travail, en le gamifiant !
Conclusion
Les évaluations, qu’elles soient manuelles ou automatiques, sont des moments cruciaux d’un parcours pédagogique.
Depuis de nombreuses années, nous essayons de les rendre les plus utiles possibles, voire même le plus fun possible, tout en essayant d’en retirer le côté stressant !
Si vous souhaitez utiliser notre LMS doté de nombreuses fonctionnalités pour les évaluations, ou si vous préférez lancer nos parcours de formation au code en marque blanche, n'hésitez pas à venir discuter avec nous !



